Der Meta Data Explorer liefert dir eine Übersicht über die wichtigsten Infos zu deiner Domain. Damit kannst du zum Beispiel folgende Szenarien analysieren:
Hast du Links auf andere Seiten, die du vergessen hast oder nicht siehst? Der Metadaten-Scrapper schaut sich den Source Code der Seite an und findet alle Links. Er sortiert diese nach externen und internen Links. So kannst du die Links deiner Webseite ganz einfach lesen.
Mit dem Tool kannst du eine Seite anfragen und es wird dir der HTTP Status Code zurückgegeben. Bei Redirects wird die URL angefragt, auf die der Redirect gesetzt wurde. Eine Redirect ist die Weiterleitung auf eine andere Seite.
Das Canonical Tag wird ausgegeben. So kannst du schnell überprüfen, ob die angefragte Seite auch der kanonischen URL entspricht.
Deine Anfrage wird verarbeitet. Meta-Daten und weitere Informationen werden gesammelt. Dies kann einige Sekunden dauern.
Hinweis
Anfrage Starten
Was ist eine Kanonische URL ?
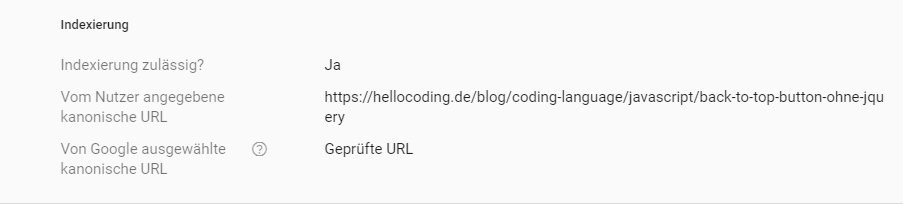
Kanonische URLs sind dazu da, Duplicate Content korrekt auszuzeichnen. Gibt es einen Artikel zum Beispiel unter zwei Kategorien, würde Google eine Abstrafung vornehmen, da der Inhalt doppelt vorhanden ist. Durch eine kanonische URL kann man Google nun sagen, welcher Artikel das Original ist. Google berücksichtigt diese; hier zum Beispiel die Ausgabe des Canonicals in der Search Console von Google.
Die Kanonische URL kannst du ganz einfach definieren:
Durch das rel Attribute wird definiert, dass die URL eine kanonische URL ist. Der href gibt die URL an. Dieses Link Tag muss im <head> der HTML Seite stehen.
## Was ist ein HTTP Status Code?
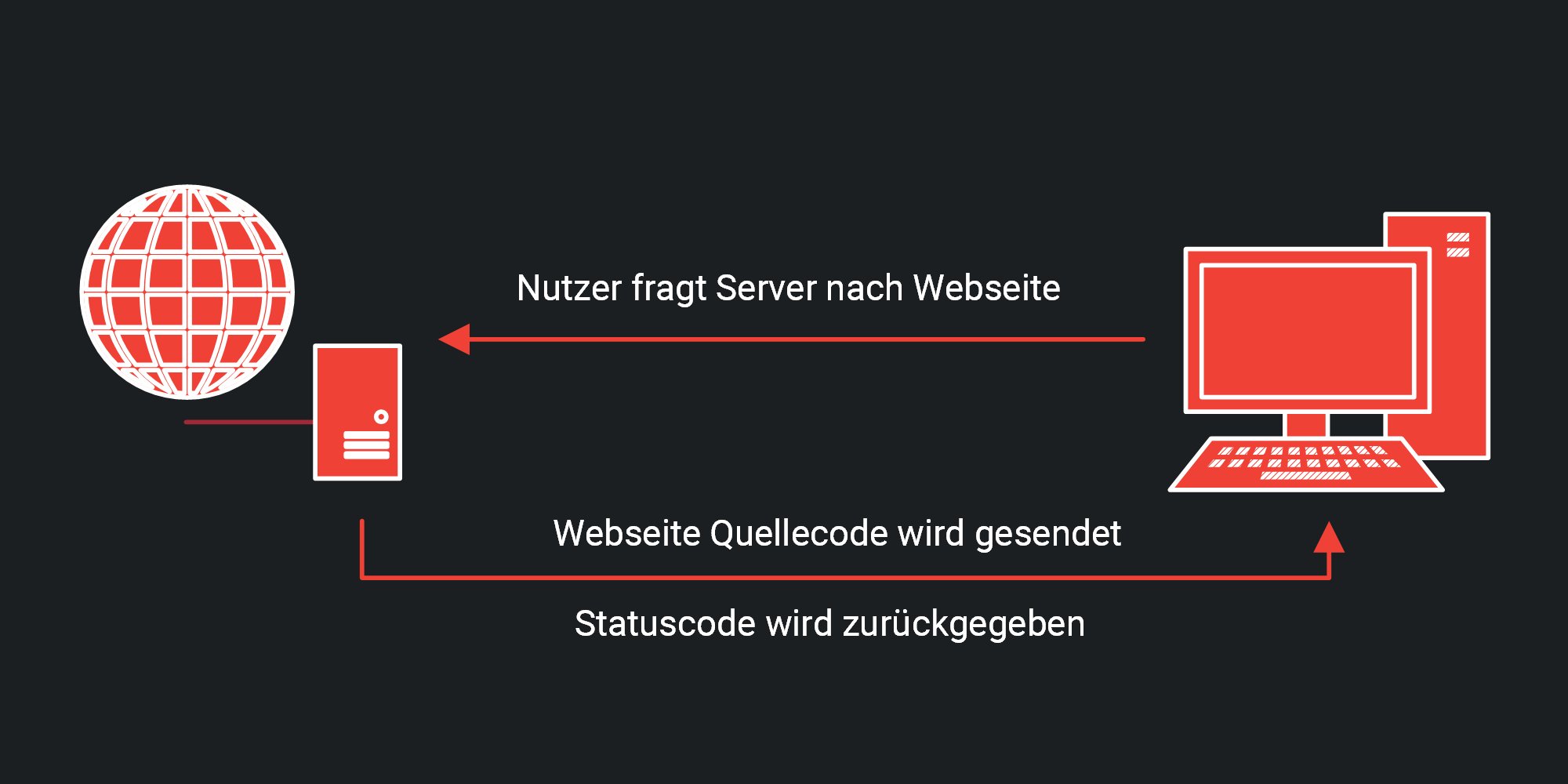
Der HTTP Status Code wird bei Anfragen an einen Server immer an den Client als Antwort zurückgegeben, um einen Erfolg der Anfrage zu identifizieren oder eben bei einem Nicht-Erfolg genauer eingrenzen zu können, warum das Dokument nicht zurückgegeben werden konnte.
Eine kleine Aufführung der häufigsten Status Codes:
Der 200 Status Code sagt aus, dass die Anfrage vom Server verarbeitet werden konnte. Daraufhin wird die Antwort zurückgegeben.
307 - Temporary Redirect
Der 307 Status Code besagt das eine Weiterleitung nur temporärer Natur ist und nach einiger Zeit sich wieder zurückändern könnte.
308 - Permanent Redirect
Der 308 Status Code besagt, dass eine Weiterleitung für immer gesetzt ist und nicht mehr ändern wird.
Die ursprüngliche Request Methode wird bei der Weiterleitung mit 307 und 308 beachtet
403 - Forbidden
Der Status Code 403 gibt meistens eine weiße Seite mit den Worten “Forbidden 403” zurück. Das heißt, der Client hat nicht die nötigen Berechtigungen um die Seite vom Server abzurufen.
404 - Not Found
Der Status Code 404 ist wohl gleich der bekannteste, da dieser erscheint, wenn eine Ressource auf dem Server nicht gefunden wurde.
418 - I’m a teapot
Mit dieser Teekanne kannst du leider keinen Kaffee im Coffee Pot Control Protocol kochen; es wurde aus Versehen eine Teekanne anstatt einer Kaffeekanne verwendet. Dieser Status Code ist eine Aprilscherz aus dem Jahr 1998.
Der 500 Fehler ist ein server-interner Fehler, heißt: Wenn du in deiner Backend Sprache (zum Beispiel PHP) einen Fehler machst, kann es sein, dass, wenn der Server dafür entsprechend konfiguriert ist, nicht die Fehlermeldung von PHP ausgegeben, sondern ein 500 Status Code zurückgegeben wird.
Backend Sprache bezeichnet die Sprache, die auf dem Server läuft, und ist im Hintergrund für den Nutzer der Webseite nicht ersichtlich.
Vorsicht vor Status Code 301 & 302
Diese sind ebenfalls für das Weiterleiten zuständig; allerdings kann es bei diesen Methoden oft vorkommen, dass ein POST Request in eine GET Request umgewandelt wird.
Primär sind vor allem URL-Hijackings der Grund dafür, dass diese Request Methoden grundsätzlich zu vermeiden sind und besser auf einen 307 oder 308 Status Code zurückgegriffen werden sollte. Diesen ist es nicht erlaubt die Request Methode zu ändern.
Was sind Metadaten?
Metadaten sind zusätzliche Informationen im <head> einer Webseite, diese helfen, die Informationen der Seite zu verstehen. Dort könnten zum Beispiel folgende Metainformationen hinterlegt sein:
Express ist ein Webserver und Framework für NodeJS, das es dir ermöglicht, Routen anzulegen, Controller einzurichten und mit Template Engines zu arbeiten.
Dafür eignet sich der Express Generator. Diese CLI bietet dir die Möglichkeit, schnell Und einfach ein kleines Template für deine Applikation zu erstellen.
Das JQuery für Node JS ist Cheerio. Nativ hat NodeJS kein Dom oder die Möglichkeit, diesen zu interpretieren, weshalb man einen Dom-Interpreter benötigt. Für diesen Zweck habe ich Cheerio verwendet.
URL - Node JS integriertes Module
Mit dem Befehl new URL() kannst du dir sowohl eine Übersicht der Parameter einer URL generieren als auch eine Relative URL in eine Absolute URL umwandeln.
Interne und Externe Links werden nun bei Unterseiten Gezählt.
Bei Überschriften wird nun die Hirachie angezeigt.
Meta Daten ohne ein Name oder Property Attribute werden nicht mehr ausgegben.
09.04.2022
Rich Results als zusätzlicher Check hinzugefügt.
Schema Markup Validator Tool Check entfernt.
PageSpeed Check ausgetauscht.
Großes Update am Design des Meta Data Explorers.
23.06.2024
Nach nun mehr als 5 Jahren wurde es Zeit, einmal den kompletten Quelltext des Meta Data Explorers zu aktualisieren. In diesem Zuge habe ich mich dafür entschieden, den ganzen Meta Data Explorer neu in Go zu schreiben. Damit einhergehend gab es noch mal einige Performance und Sicherheits-Optimierungen.
Hinterlasse mir gerne einen Kommentar zum Artikel und wie er dir weitergeholfen hat beziehungsweise, was dir helfen würde das Thema besser zu verstehen. Oder hast du einen Fehler entdeckt, den ich korrigieren sollte? Schreibe mir auch dazu gerne ein Feedback!
Facebook
Twitter
Telegram
WhatsApp
Mail
Artikel wurde Zuletzt aktualisiert am 23.06.2024.
Bildquelle - Vielen Dank an die Ersteller:innen für dieses Bild
den Metadata-Explorer finde ich toll! Habe ihn zwar noch nie verwendet geschweige denn gebraucht, aber ich kann mir vorstellen, dass dieses Tool für SEO Fanatiker nützlich ist. Ich hoffe mein kleiner Kommentar gefällt dir.
es freut mich das dir der Metadata-Explorer gefällt. Ja für SEO's ist es manchmal ganz nützlich Redirects sofort zu erkennen, oder auch 404 Links auf einer Seite.
Danke für dein Feedback, das freute mich! Weitere Tools findest du in der Kategorie Generatoren, wobei diese hier definitiv das Ausführlichste zurzeit ist. Ich hab definitiv noch Ideen für weitere klein Helferlein. :)






Moin, ich mach' mal den Anfang
den Metadata-Explorer finde ich toll! Habe ihn zwar noch nie verwendet geschweige denn gebraucht, aber ich kann mir vorstellen, dass dieses Tool für SEO Fanatiker nützlich ist. Ich hoffe mein kleiner Kommentar gefällt dir.
LG so'n Typ aus deinem Discord Forum