Manchmal ist es notwendig Prozesse im Browser zu automatisieren oder die Funktionalitäten von Webseiten in regelmäßigen Abständen automatisiert zu testen und beim Fehlschlagen eine Information darüber zu erhalten. So kannst du Fehler schnellstmöglich beheben, damit deine Benutzer diese nicht erst melden müssen.
Selenium kann man auch zur Automatisierung verwenden. Vielleicht hast du eine kleine Webseite oder firmeninterne Webseite, auf der du immer zum Zeitpunkt X Daten eintragen musst, erhältst die Daten aber eigentlich auch automatisiert und könntest diese per API senden. Aber da es nur eine kleine firmeninterne Webseite ist und kein großes Budget da ist, um eine API zu ergänzen, ist das automatisierte Steuern vom Browser vielleicht eine Übergangslösung.
Ein letzter Anwendungsfall ist das Auslesen von Daten aus Webseiten mit JavaScript, denn mit einem Browser kann dieses ausgeführt werden. Bei einer einfachen Abfrage mit request kann das nicht erfolgen, da kein JavaScript Interpreter gestartet wird.
 SeleniumHQ/selenium
SeleniumHQ/selenium
<div class="info-line">
<span class="star-count">34.265</span>
<span class="issues">186</span>
<span class="forks">8.694</span>
</div>
<p>A browser automation framework and ecosystem.</p>
<div class="topics">
<a title="dotnet in Github öffnen" href="https://github.com/topics/dotnet" rel="nofollow" class="topic">dotnet</a>
<a title="java in Github öffnen" href="https://github.com/topics/java" rel="nofollow" class="topic">java</a>
<a title="javascript in Github öffnen" href="https://github.com/topics/javascript" rel="nofollow" class="topic">javascript</a>
<a title="python in Github öffnen" href="https://github.com/topics/python" rel="nofollow" class="topic">python</a>
<a title="ruby in Github öffnen" href="https://github.com/topics/ruby" rel="nofollow" class="topic">ruby</a>
<a title="rust in Github öffnen" href="https://github.com/topics/rust" rel="nofollow" class="topic">rust</a>
<a title="selenium in Github öffnen" href="https://github.com/topics/selenium" rel="nofollow" class="topic">selenium</a>
<a title="webdriver in Github öffnen" href="https://github.com/topics/webdriver" rel="nofollow" class="topic">webdriver</a>
</div>
<div>
<a class="btn" data-icon="add_box" href="https://github.com/SeleniumHQ/selenium" title="SeleniumHQ/selenium">Github Öffnen</a>
</div>
</div>In diesem Fall ist die Selenium WebDriver API genau das richtige Tool für dich. Damit kannst du einen Browser deiner Wahl mit verschiedenen Befehlen steuern und damit Interaktion eines Benutzers nachbauen. In unserem Beitrag zeige ich dir die Einrichtung von WebDrivern für Chrome, Firefox und Safari. Die API kannst du nicht nur mit Python verwenden, sondern zum Beispiel auch mit C#, Java, Kotlin, JavaScript, PHP, Ruby oder Rust. Da es eine API ist, kann man auch für jede andere beliebige Programmiersprache einen eigenen Wrapper dafür schreiben.
Alle Code-Beispiele die ich im nachfolgenden Artikel zeigen werde um Selenium zu Erklären sind, in einem Git-Repository abgelegt, sodass man diese selber herunterladen und testen kann. Du brauchst nur die richtigen Treiber für dein Betriebssystem im Ordner driver abzulegen.
fschuermeyer/hellocoding-selenium-examples
<div class="info-line">
<span class="star-count">0</span>
<span class="issues">0</span>
<span class="forks">0</span>
</div>
<p>Selenium Beispiel für HelloCoding Artikel</p>
<div class="topics">
</div>
<div>
<a class="btn" data-icon="add_box" href="https://github.com/fschuermeyer/hellocoding-selenium-examples" title="fschuermeyer/hellocoding-selenium-examples">Github Öffnen</a>
</div>
</div>Die Installation von Selenium selbst geht über den Paketmanger von Python: pip. Mit diesem kannst du das Paket "Selenium" und viele weitere ganz einfach installieren.
Mit dem Befehl kannst du Selenium Installieren über den Paketmanager PIP. Nach der Installation kannst du zur Einrichtung der WebDriver selbst übergehen.
pip install seleniumDie WebDriver sind das Bindeglied zwischen der Programmiersprache (in unserem Fall Python) und dem Browser selbst. Ich habe dir eine Tabelle mit den Treibern für die bekanntesten Browser erstellt.
Wichtig: Du brauchst nicht nur den WebDriver, sondern das Gerät muss auch immer den Browser installiert haben, den du verwendest.
| Browser | Betriebsystem | Download |
|---|---|---|
| Chromium | Windows, Linux, macOS | Chrome Driver |
| Firefox | Windows, Linux, macOS | Firefox Driver |
| Edge | Windows 10, Linux, macOS | Edge Driver |
| Edge Legacy | Windows 10 | Edge Driver Legacy |
| Internet Explorer | Windows | Internet Explorer Driver |
| Safari | macOS | Bereits Integriert |
Den Treiber für Chrome bekommst du auf der folgenden Webseite: https://chromedriver.storage.googleapis.com/index.html. Dort findest du diesen für alle möglichen Chrome Versionen und das für Linux, macOS und Windows.
Bei dem Chrome WebDriver ist es wichtig, dass du die richtige Version zu deinem aktuellen Browser herunterlädst, bei Firefox muss zum Beispiel nicht ein spezifischer Treiber für jede Version gewählt werden.
Nach dem Herunterladen des Treibers solltest du diesen so ablegen, dass du ihn vom Python Skript aus per Pfad-Angabe leicht erreichen kannst.
Nun zeig ich dir den eigentlichen Code. Die Einrichtung des Treibers in Python folge immer dem folgenden Schema: webdriver.<browsername> wird aufgerufen und der Parameter xcutable_path wird entsprechend gesetzt, abhängig davon, wo der Treiber liegt.
In unserem Fall hab ich eine kleine Funktion eingebaut, die das "CWD" (Current Working Directory) für diese Datei auf den Pfad des aktuellen Skripts legt, sodass ich relative Pfad-Angaben vom Skript aus machen kann, auch wenn ich es aus einem anderen Verzeichnis heraus ausführen würde.
from selenium import webdriver
import os
# Current Working Directionary auf den Pfad des aktuellen Skripts setzen
os.chdir(os.path.dirname(os.path.abspath(__file__)))
driver = webdriver.Chrome(executable_path='../driver/chromedriver')
driver.maximize_window()
driver.get("https://www.hellocoding.de")Dieses kleine Beispiel startet den Chrome Browser, öffnet ihn in einem maximierten Fenster und ruft dann die Startseite von HelloCoding.de ab.
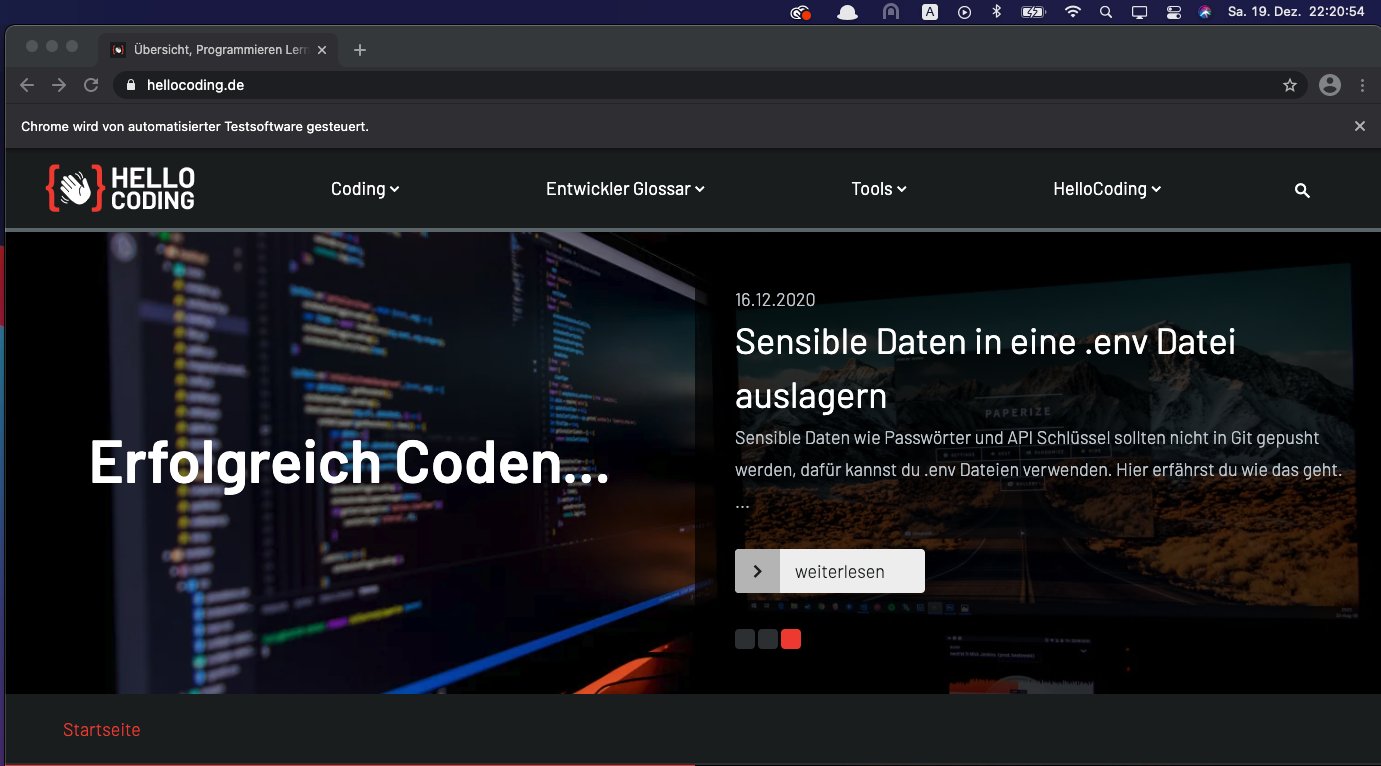
Das Fenster könnte zum Beispiel so aussehen. In Chrome gibt es einen zusätzlichen grauen Balken mit einem Hinweis darauf, dass es sich bei dem Fenster um eine automatisierte Testumgebung handelt.
Der Treiber für Firefox heißt "Gecko Driver", da die Rendering Engine von Firefox ebenfalls "Gecko" heißt. Den Treiber findest du auf der folgenden Github Seite. Gecko wird ebenfalls von Windows, macOS und Linux unterstützt.
Das Code-Beispiel macht das gleiche wie das Vorherige. Als Erstes setze ich wieder den Arbeitspfad auf den Pfad des Skripts selbst. Dann wird das Fenster geöffnet, maximiert und abschließend wird HelloCoding.de aufgerufen.
from selenium import webdriver
import os
os.chdir(os.path.dirname(os.path.abspath(__file__))) # Current Working Directionary auf den Pfad des aktuellen Skripts setzen
driver = webdriver.Firefox(executable_path='../driver/geckodriver')
driver.maximize_window()
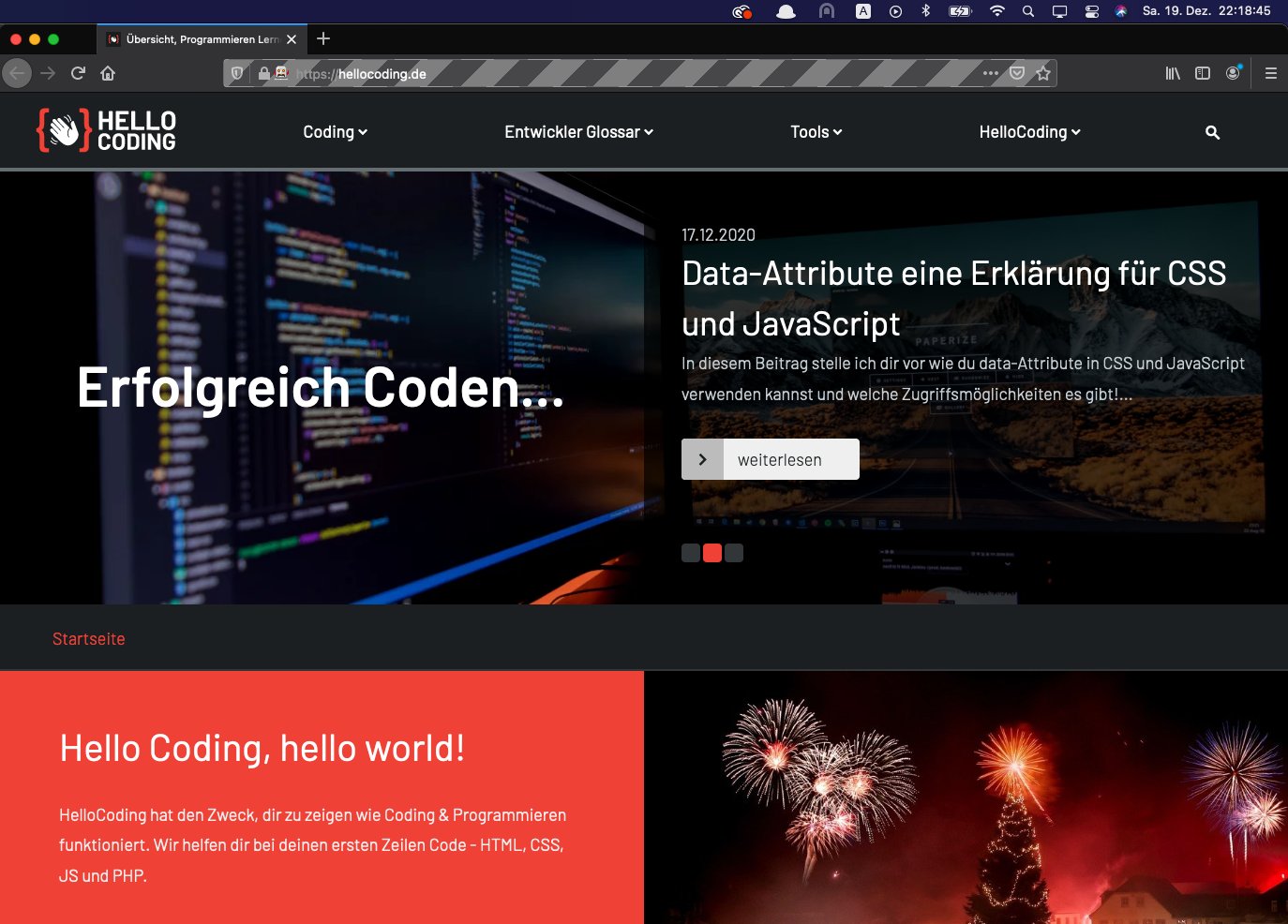
driver.get("https://www.hellocoding.de")Die automatisierte Testumgebung bei Firefox erkennst du am grau-gestreiften Design in der Suche/URL Leiste und an dem kleinen Roboter vor der URL.
Bei macOS muss der Befehl safaridriver --enable ausgeführt werden, um den WebDriver zu aktivieren. Im Vergleich zu den anderen Browsern ist kein vorheriges Herunterladen eines WebDrivers notwendig. Da Safari nur für macOS entwickelt wird, funktioniert natürlich auch Selenium mit Safari nur auf Geräte mit macOS als Betriebssystem.
Das Skript selbst ist wieder mit der gleichen Funktionalität ausgestattet, wie bei den Beispielen zuvor. Safari wird gestartet, anschließend wird das Fenster maximiert und zuletzt HelloCoding.de aufgerufen.
from selenium import webdriver
driver = webdriver.Safari()
driver.maximize_window()
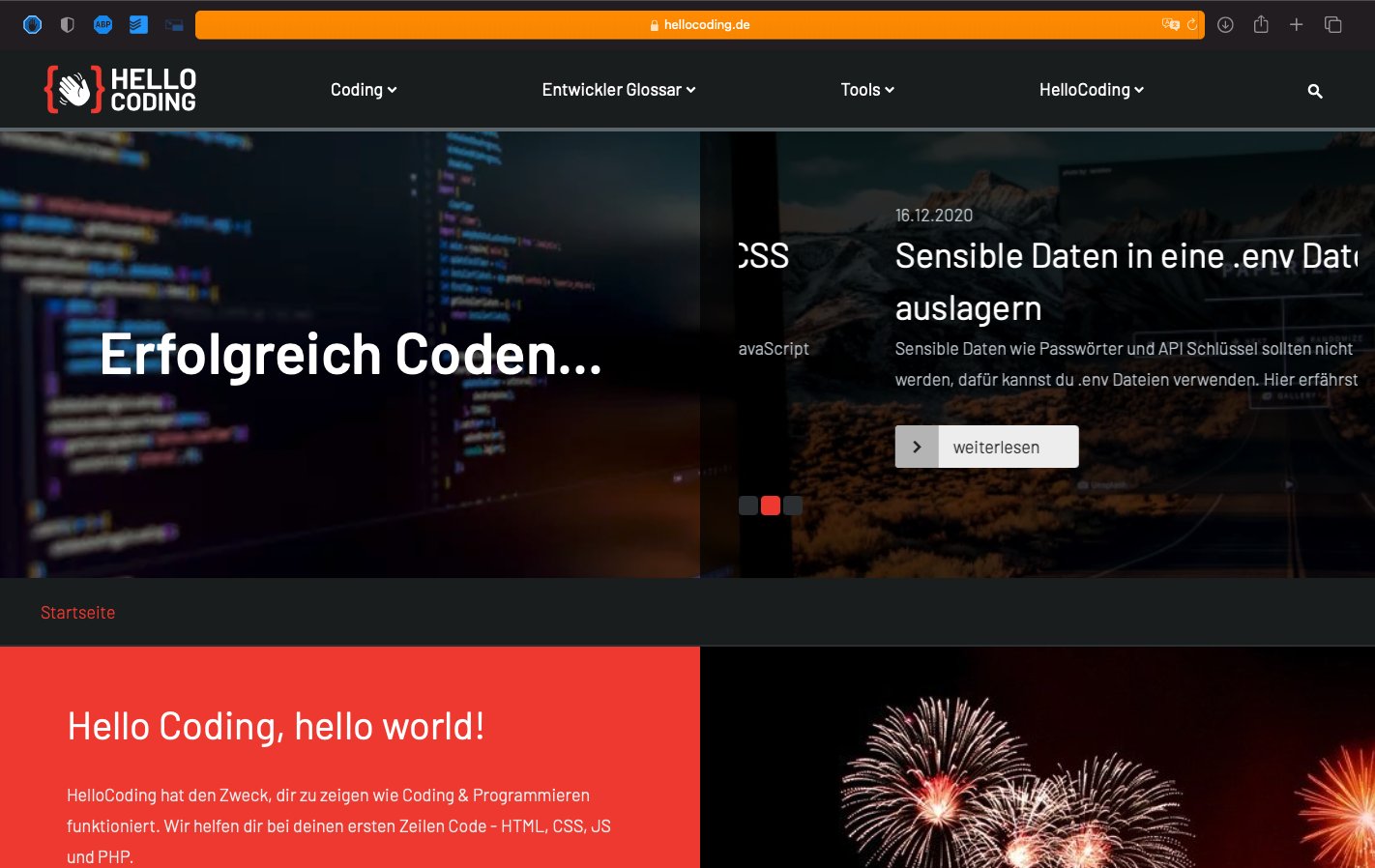
driver.get("https://www.hellocoding.de")In Safari erkennst du die automatisierte Steuerung des Browsers an dem orangen Balken im Suchfeld. Der nachfolgende Screenshot zeigt wie unser Fenster aussieht, das vom Python Skript erstellt wurde.
Es folgt eine Auflistung von verschiedenen Möglichkeiten zum Selektieren von Elementen. Dabei wird zwischen der Selektierung einzelner und mehrerer Elemente unterschieden. Je nachdem, ob du einzelne oder mehrere Elemente Selektieren möchtest, gibt es verschiedene Methoden.
Die Methoden zur Selektierung einzelner Elemente beginnen mit find_element_by_ und sind in der folgenden Tabelle dargestellt.
| Name | Beschreibung |
|---|---|
| find_element_by_id | Element anhand des Attributes "id" finden. |
| find_element_by_link_text | Element anhand des Textes eines Links finden. |
| find_element_by_partial_link_text | Element anhand eines Teiles des Textes von einem Link finden. |
| find_element_by_name | Element anhand des Attributes "name" finden - das ist für Formularfelder nützlich. |
| find_element_by_tag_name | Element anhand des Tag-Namens finden. |
| find_element_by_class_name | Element anhand einer CSS Klasse finden. |
| find_element_by_xpath | Element anhand eines xPaths finden. |
| find_element_by_css_selector | Element anhand eines CSS-Selektors finden. |
Die Methoden zur Selektierung mehrerer Elemente fangen mit find_elements_by_ an und sind in der folgenden Tabelle erklärt.
| Name | Beschreibung |
|---|---|
| find_elements_by_link_text | Elemente anhand der Texte von Links finden. |
| find_elements_by_partial_link_text | Elemente anhand eines Teils des Textes von einem Link finden. |
| find_elements_by_name | Element anhand des Attributes "name" finden - das ist für Formularfelder nützlich. |
| find_elements_by_tag_name | Elemente anhand der Tag-Namen finden. |
| find_elements_by_class_name | Elemente anhand einer CSS Klasse finden. |
| find_elements_by_xpath | Elemente anhand eines xPaths finden. |
| find_elements_by_css_selector | Elemente anhand eines CSS-Selektors finden. |
Jetzt schauen wir uns an, wie wir Elemente mit CSS-Selektoren und xPath selektieren können.
Ich persönlich bin mit CSS-Selektoren deutlich besser vertraut als mit xPath, da ich diese täglich in meinem beruflichen Alltag verwende. Trotzdem darf man xPath nicht unterschätzen, da man zum Beispiel bei xPath Eltern Elemente selektieren kann, was bei CSS ohne den zusätzlichen Einsatz von JavaScript unmöglich ist.
Die Variante mit xPath Selektoren ist deutlich umfangreicher als die CSS Variante und wie ich finde auch komplizierter zu verstehen.
Der CSS-Selektor würde in xPath deutlich länger und komplizierter zu schreiben sein.
Als Beispiel nehmen wir folgende Überschrift, die wir jeweils über CSS und xPath selektieren wollen.
<body>
<div>
<h1 class="test" id="test">Überschrift</h1>
</div>
</body>Ein Beispiel eines CSS-Selektors:
body>div h1#test.testDer gleiche Ausdruck als xPath:
.//body/div//h1[@id="test"][contains(concat(" ",normalize-space(@class)," ")," test ")]Wie du siehst, ist es deutlich einfacher einen CSS Selektor zu schreiben, als einen xPath Selektor.
Aber es gibt auch hier einen Vorteil. Du kannst Eltern Elemente selektieren, oder auch kleine if-Abfragen schreiben und hast Funktionen wie contains zur Verfügung. Außerdem kann xPath Elemente relativ zu anderen Elementen selektieren, was bei CSS nicht einfach möglich ist, wenn ein Element kein eindeutiges Attribut besitzt.
Ich habe dir hier ein Cheat Sheet herausgesucht, das dir die xPath Selektor-Schreibweise näher bringt: https://devhints.io/xpath
Abschließend ein Beispiel, wie du xPath Selektoren in Selenium verwenden kannst. Über den ersten Aufruf erhalten wir ein h1 Element von der Webseite, im Zweiten erhalten wir eine Liste von p Elementen.
driver.find_element_by_xpath('.//html//body//h1')
driver.find_elements_by_xpath('.//html//body//p')Die Selektierung über CSS-Selektoren ist die Standard-Variante in Browsern um Elemente zu selektieren. Falls du kein Webentwickler bist, kann ich dir das Cheatsheet von DEVHINTS empfehlen. Dort findest du einen kurzen Überblick über die Selektoren.
Ein Beispiel, wie du CSS-Selektoren in Selenium verwenden kannst. Über den ersten Aufruf erhalten wir ein h1 Element von der Webseite, über den Zweiten erhalten wir eine Liste von p Elementen.
driver.find_element_by_css_selector('html body h1')
driver.find_elements_by_css_selector('html body p')Manchmal ist es notwendig auf Elemente zu warten, da man zum Beispiel weiß, dass sie auf der Seite erscheinen werden und, dass durch andere Elemente der Webseite die Ausgabe dieser Elemente verzögert wird.
Für das Warten auf Elemente müssen wir einige Pakete importieren.
from selenium.webdriver.common.by import ByBy hält verschiedene Selektierungs-Möglichkeiten bereit. Unter anderem die Selektierung über CSS-Selektoren sowie xPath.
Das Paket expected_conditions hält verschiedene Möglichkeiten bereit, um auf Elemente zu warten. Zum Beispiel title_is, title_contains und element_to_be_clickable. Letzteres verwenden wir, um zu prüfen, ob ein Element vorhanden ist.
from selenium.webdriver.support import expected_conditions as ECWebDriverWait kann auf eine "Expected Condition" warten. Wenn die angegebene Maximal-Zeit überschritten wird, kommt es zu einer TimeoutException. Diese kann bequem abgefangen werden, also der Fall, dass das Element in einer vorgegebenen Zeit nicht auf der Seite erscheint.
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutExceptionEs folgt ein Code-Beispiel welches prüft, ob ein Element auf der Seite vorhanden ist. In diesem Fall wird das Element angeklickt. Als Ziel wählen wir den "Cookie Einstellungen" Button.
Falls das Element nicht vorhanden ist, kommt es zu einer TimeoutException nach 10 Sekunden.
try:
wait = WebDriverWait(driver, 10)
element = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#CookieSettings > div > div > div > div > a')))
element.click()
except TimeoutException as error:
failed = TrueDas Warten auf Elemente Funktioniert eigentlich ziemlich Einfach und kann Theoretisch auch schnell selbst Programmiert werden. Es wird alle 500ms eine Abfrage gemacht ob das Element Vorhanden ist falls nicht wird weitere 500ms gewartet anderen falls wird das Element zurück gegeben. Falls nach Ablauf der Angegeben Zeit immer noch kein Element gefunden wurde wird eine TimeoutException gefeuert.
Kommen wir jetzt zu einer der wichtigsten Funktionen von Selenium: dem Klicken und der Eingabe von Tasten. Ohne diese Funktionalität ergibt Selenium in der Verwendung wenig Sinn, da es ohne diese Optionen keine Möglichkeiten der Interaktion gibt. Als Beispiel zum Klicken und der Tastatureingaben, habe ich ein kleines zusammenhängendes Skript erstellt, mit dem du die Suche auf HelloCoding.de automatisiert ansteuern kannst:
driver.get("https://www.hellocoding.de")
driver.find_element_by_css_selector('#navigation-handler > ul > li.search.noChildren > a').click()
driver.find_element_by_css_selector('form.col-md-12 > input:nth-child(2)').send_keys('JavaScript')
driver.find_element_by_css_selector('button.btn.search-icon').click()Um ein Element zu klicken, benötigst du nur die Methode click. Diese ist für alle Elemente verfügbar. Die click Methode selbst hat keine weiteren Argumente.
driver.find_element_by_css_selector('#navigation-handler > ul > li.search.noChildren > a').click()Tastatureingaben können, ähnlich wie beim Klicken, relativ einfach getätigt werden. Mit der Methode send_keys können wir Tastatureingaben tätigen.
driver.find_element_by_css_selector('form.col-md-12 > input:nth-child(2)').send_keys('JavaScript')Für spezielle Schlüssel ("Special Keys") kann man auf vordefinierte Werte zugreifen. Diese sind unter common.keys abgelegt. Einen bestimmten Key können wir danach wie folgt abrufen.
from selenium.webdriver.common.keys import Keys
driver.find_element_by_css_selector('input').send_keys(Keys.NUMPAD9)Die folgenden Keys sind in common.keys vorhanden und können verwenden werden:
Quelle: https://www.selenium.dev/selenium/docs/api/py/webdriver/selenium.webdriver.common.keys.html
In Python ist es auch möglich Screenshots von der Webseite zu erstellen, auf der du dich befindest. Dafür wird die Methode save_screenshot verwendet. Falls du einen Pfad angibst, solltest du darauf achten, dass dieser bereits vorher existiert. Ansonsten wird der Screenshot nicht erstellt. Die Funktion gibt True oder False zurück, so kannst du eine eigene Prüfung einbauen. Das kann zum Beispiel so aussehen:
if driver.save_screenshot('screenshots/selenium-test.png'):
print("Erfolgreich Erstellt")
else:
print("Screenshot konnte nicht Erstellt werden")Manchmal kommt es vor, dass man bestimmte Interaktionen vornehmen will, die sich nicht so einfach mit Selenium bewerkstelligen lassen. Zum Beispiel bestimmte JavaScript Variablen abfragen.
Als Beispiel fragen wir die Variable window.location ab und lassen uns die Werte in Python ausgeben. Du kannst auch Werte des Objekts window.location direkt abfragen, was je nach Anwendung sicherlich nützlich sein kann.
location = driver.execute_script("return window.location")
print(location)
print(location['host'])Die Browser Chrome und Firefox unterstützen beide die Option headless zu laufen, das heißt ohne grafisches Benutzerinterface, sondern nur als Prozess im Hintergrund. Der Vorteil davon ist, dass du so automatische Tests auch im Hintergrund laufen lassen und parallel andere Sachen erledigen kannst. Bei einem Nicht-Headless-Browser würde sich das Fenster in den Vordergrund schieben, wenn du es startest. Das kann äußerst störend sein, wenn du mehrere Fenster öffnen willst.
Um Firefox im Headless-Mode zu starten, müssen wir das Argument --headless beim Start übergeben. Danach wird der Browser ohne eine GUI gestartet, also nur als Hintergrundprozess.
options = webdriver.firefox.options.Options()
options.add_argument('--headless')
driver = webdriver.Firefox(options=options,executable_path='../driver/geckodriver')Der Aufbau, um Chrome im Headless-Mode in Python zu starten, ist sehr ähnlich zu dem Code vom Firefox. Wir tauschen nur das Wort "Chrome" durch "Firefox" aus. Das Argument zum Starten im Headless-Mode ist wieder --headless.
options = webdriver.chrome.options.Options()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options,executable_path='../driver/chromedriver')Nun wollen wir uns anschauen, wie man eine Test Suite erstellen kann. Dafür benötigen wir weitere Module.
Für unsere Tests wenden wir das Wissen aus den ersten Beispielen an. Wir erstellen 2 Tests: der Erste prüft, ob die Webseite aufgerufen werden kann. Diesen Test nennen wir test_loading_website. Der zweite Test stellt sicher, dass keine der Webseiten den Fehlercode 500 zurückgibt. Das erreichen wir, indem wir uns alle Links aus der Sitemap holen und dann den Quellcode der Seiten mit dem Text vergleichen, den ich bei HelloCoding für 500er Fehler definiert habe.
Wir können mit Selenium nicht direkt auf HTTP Status Codes zugreifen, deshalb empfiehlt sich diese Variante zu nutzen. Alternativ kannst du das request Modul nutzen, um dir die Status Codes zu holen. Je nach Test ergibt die Kombination von Selenium und Request Sinn.
# Imports für die Tests
import unittest
import HtmlTestRunner
# Standard Import für korrekten Pfad
import os
# Selenium Imports
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
# Current Working Directory auf den Pfad des aktuellen Skripts setzen
os.chdir(os.path.dirname(os.path.abspath(__file__)))
class HelloCodingTestSuit(unittest.TestCase):
baseUrl="https://hellocoding.de"
sitemapUrl="https://www.hellocoding.de/sitemap"
# Wird vor den Tests aufgerufen
def setUp(self):
self.driver = webdriver.Chrome(executable_path='../driver/chromedriver')
self.driver.maximize_window()
self.driver.implicitly_wait(5)
# Homepage laden
def test_loading_website(self):
self.driver.get(self.baseUrl)
# Teste, ob die korrekte Webseite geladen wurde
self.assertIn("Übersicht, Programmieren Lernen | HelloCoding",self.driver.title)
# Teste, ob eine Seite einen 500er Fehler hat
def test_no_error(self):
self.driver.get(self.sitemapUrl)
failed = True
wait = WebDriverWait(self.driver, 5)
# Alle Links aus der Sitemap holen
try:
element = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#contentTOC')))
elements = element.find_elements_by_css_selector('.sitemap-widget ul li a')
except TimeoutException as error:
pass
if len(elements) != 0:
links = []
for a in elements:
links.append(a.get_attribute('href'))
# Jeden Link auf den 500er Fehler prüfen
for link in links:
if link != "":
self.driver.get(link)
if "500er - Server Fehler" in self.driver.page_source:
self.fail(link + " - 500er Fehler")
else:
self.fail('Keine Elemente Gefunden')
# Abschließende Funktion am Ende aller Test Cases
def tearDown(self):
# Browser schließen
self.driver.quit()
if __name__ == '__main__':
unittest.main(testRunner=HtmlTestRunner.HTMLTestRunner(output='./report'))Wenn wir nun unsere Unittest ausführen, erhalten wir eine HTML Datei, die folgende Ausgabe enthalten kann. Dort sehen wir, dass eine Seite einen 500er Fehler zurückgegeben hat und auch direkt, welche Seite das war. Aber das Laden der Startseite war schon einmal erfolgreich.

So könnte man noch weitere Fälle abdecken, wie das Versenden von Kommentaren und Formularen, oder das Verwenden der Suche.
Du könntest zum Beispiel diesen Test über eine Cronjob alle 3 Tage auf einem Server ausführen lassen und dir das Ergebnis per Mail zusenden lassen. So hast du dann ein Monitoring das angibt, ob deine Webseite korrekt funktioniert, oder sich ein Fehler eingschlichen hat.
Zuletzt will ich dir 3 Praxisbeispiele an die Hand geben, die ich für dich geschrieben habe, mit denen du folgende Dinge tun kannst:
Falls du danach noch Fragen haben solltest, kannst du die Kommentarsektion am Ende des Artikels nutzen, oder auf unserem Discord Server vorbeischauen!
Als Erstes wollen wir die Google Suche steuern und dort die Titel der 10 obersten Suchergebnissen auslesen.
Das Skript habe ich auf den Safari-Browser ausgelegt, kann aber ebenso gut mit Chrome und Firefox verwendet werden.
Eine Besonderheit ist hier, dass wir die Methode switch_to.frame verwenden, um auch einen iFrame Steuern zu können, da dann der driver auf den iFrame zeigt. Diese ist notwendig da das Fenster mit den Datenschutzeinstellungen bei Google ein iFrame ist. Mit switch_to.parent_frame können wir wieder unser eigentliches Fenster steuern.
Am Ende erhalten wir mit getAttribute('innerHTML') die Titel der verschiedenen Suchergebnisse und erstellen daraus eine entsprechende Liste. Diese könnte man zum Beispiel für ein W-Fragen Tool verwenden.
Ein letzter Hinweis: die Google Webseite ändert sich regelmäßig, also kann es gut sein, dass dieses Beispiel schon nicht mehr funktioniert, wenn du es anwendest. Dieses Beispiel soll dir nur einen Eindruck davon geben, wie ein Skript zur Browser-Automatisierung für so einen Fall grundsätzlich aussehen könnte.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from time import sleep
driver = webdriver.Safari()
# Wait Instanz erstellen
wait = WebDriverWait(driver, 5)
# Fenster maximieren
driver.maximize_window()
driver.get("https://www.google.de")
sleep(5)
# iFrame mit der Datenschutz Einstellung suchen
privacyiFrame = driver.find_elements_by_css_selector('iframe')
# Wenn der iFrame da ist, auf diesen wechseln und den "Zustimmen" Button drücken.
if privacyiFrame:
driver.switch_to.frame(0)
driver.find_element_by_id('introAgreeButton').click()
# Zurück zum Eltern Fenster wechseln
driver.switch_to.parent_frame()
# Das Suchfeld finden. Es hat immer den Namen q - Das ist bei einigen Seiten der Fall, zum Beispiel auch bei Wordpress Seiten.
element = driver.find_element_by_name('q')
# Suchbegriff eingeben
element.send_keys('Google with Safari Automatisation')
# Suche absenden
element.send_keys(Keys.RETURN)
# Variable für den Fall, das keine Suchergebnisse gefunden werden
failed = False
# Prüfen, ob das Element mit den Suchergebnissen vorhanden ist. Falls ja, kann mit den einzelnen Ergebnissen fortgefahren werden.
try:
element = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#search')))
search_results = element.find_elements_by_css_selector('.g')
except TimeoutException as error:
failed = True
if failed != True:
titles = []
# Über die Suchergebnisse iterieren
for search_item in search_results:
try:
item = WebDriverWait(search_item, 5)
# Titel Element abrufen
title_elm = item.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'h3 > span')))
# Text aus dem Titel nehmen
titles.append(title_elm.get_attribute('innerHTML'))
except TimeoutException as error:
pass
driver.quit()
print(titles)Als zweites Beispiel habe ich mir ausgesucht, automatisiert Kontaktformulare auszufüllen. Als Beispiel habe ich dafür eine JSON Datei mit den Werten angelegt siehe nachfolgende JSON Datei. Falls du mehr dazu wissen willst, wie du mit JSON in Python arbeiten kannst, dann schau dir diesen Artikel an.
Die Beispiel JSON Datei ist wie folgt aufgebaut: Es gibt ein Array mit mehreren Objekten, in denen sich wiederum Zuordnungen zu unseren 4 verschiedenen Felder im Kontaktformular befinden, die wir ausfüllen können.
[
{
"name": "Hans",
"thema": "Python CSV Erstellen",
"discord": "hans#0000",
"email": "hans@hellocoding.de"
},
{
"name": "Max",
"thema": "Python JSON Erstellen",
"discord": "max#0000",
"email": "max@hellocoding.de"
}
]Das Formular, das wir absenden wollen, ist das Folgende: https://hellocoding.de/artikel-idee. Dort kannst du mir Themenvorschläge für neue Artikel senden.
Das eigentliche Ausfüllen des Formulars ist über die send_keys Methode möglich. Abschließend prüfen wir, ob das Element mit der Klasse form-message-success sichtbar ist. Da dieses Element das CSS Attribut display: block erhält, wenn das Formular erfolgreich versendet wurde, ist es ein guter Indikator dafür, dass das Formular abgeschickt wurde. Mit einer Schleife können wir das Formular auch mehrmals abschicken.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import os
import json
from time import sleep
# Current Working Directory auf den Pfad des aktuellen Skripts setzen
os.chdir(os.path.dirname(os.path.abspath(__file__)))
driver = webdriver.Firefox(executable_path='../driver/geckodriver')
# Fenster maximieren
driver.maximize_window()
url = "https://hellocoding.de/artikel-idee"
# Daten aus dem JSON File laden
with open('fill.json','r') as file:
obj = json.loads(file.read())
# WebDriverWait Instanz, um später auf das erfolgreiche Versenden warten zu können.
wait = WebDriverWait(driver, 5)
# Das Formular mehrmals ausfüllen, mit allen vordefinierten Werten aus dem JSON
for data in obj:
# URL abrufen
driver.get(url)
# Feld Name mit entsprechenden Werten aus dem JSON ausfüllen
driver.find_element_by_name('Name').send_keys(data['name'])
driver.find_element_by_name('Thema').send_keys(data['thema'])
driver.find_element_by_name('Discord Name').send_keys(data['discord'])
driver.find_element_by_name('sender-mail').send_keys(data['email'])
driver.find_element_by_name('privacy').click()
driver.find_element_by_name('anfrage-senden').click()
# Prüfen, ob das Senden rrfolgreich war. Falls nicht tue nichts und versuche den nächsten zu versenden.
try:
wait.until(EC.visibility_of_element_located((By.CSS_SELECTOR, '.form-message-success')))
except TimeoutException as error:
pass
driver.quit()Für dieses Beispiel habe ich mir etwas Einfaches überlegt: Wir holen uns aus der Seite "Sitemap" von HelloCoding.de alle Links heraus, die dort definiert sind, rufen alle Seiten aus der Sitemap nacheinander ab und speichern jeweils einen Screenshot. Damit wir die Namen der Bilder leserlich speichern können, verwende ich das Modul slugify (https://pypi.org/project/python-slugify/). Das sorgt für saubere Dateinamen.
Mit der Methode get_attribute holen wir uns das href-Attribut, also den Link, den wir abrufen wollen. Über diese Liste an Links wird nun iteriert, für jeden Link ein Screenshot erstellt und wir erhalten einen Ordner mit etlichen Screenshots.
Wofür könnte das Interessant sein? Du kannst zum Beispiel prüfen, ob auf allen Seiten das Design stimmt. Anstatt jede Seite aufzurufen, musst du nur noch durch einen Ordner von Screenshots gehen.
from selenium import webdriver
import os
from time import sleep
from slugify import slugify
# Current Working Directory auf den Pfad des aktuellen Skripts setzen
os.chdir(os.path.dirname(os.path.abspath(__file__)))
driver = webdriver.Chrome(executable_path='../driver/chromedriver')
# Fenster maximieren
driver.maximize_window()
# Sitemap abrufen
driver.get("https://www.hellocoding.de/sitemap")
sleep(4)
# Alle Links auslesen
elements = driver.find_elements_by_css_selector('#contentTOC .sitemap-widget ul li a')
# Eine Liste mit allen Links erstellen
links = []
for a in elements:
links.append(a.get_attribute('href'))
# Alle Webseiten abrufen und jeweils einen Screenshot erstellen.
for link in links:
driver.get(link)
sleep(2)
driver.save_screenshot('../screenshot-example/' + slugify(link) + '.png')
driver.quit()Selenium ist eine mächtige API um den Browser fernzusteuern und in Kombination mit Python hast du eine syntaktisch einfache Sprache an der Hand, mit der du deine Browser-Tests schreiben kannst. Natürlich kannst du auch Selenium mit Python Unittest kombinieren!
Dir sind keine Grenzen in dem gesetzt, was du mit dem Paket Selenium umsetzen kannst. Bedenke nur immer, dich an die Vorgaben der Webseiten-Betreiber zu halten, falls du Selenium auf fremden Webseiten einsetzt!
Hinterlasse mir gerne einen Kommentar zum Artikel und wie er dir weitergeholfen hat beziehungsweise, was dir helfen würde das Thema besser zu verstehen. Oder hast du einen Fehler entdeckt, den ich korrigieren sollte? Schreibe mir auch dazu gerne ein Feedback!
Es sind noch keine Kommentare vorhanden? Sei der/die Erste und verfasse einen Kommentar zum Artikel "Python Browser Automatisierung mit Selenium"!


